How I Automated My Bike Shop
Web Scraping With Nokogiri and Mechanize #
Ever since I can remember I have loved mountain biking. From doing Ride the Rockies with my family at the age of 8 to riding gnarly, technical downhill trails up at Whistler Bike Park, in British Columbia, Canada, I have spent a huge chunk of my life cruising on two wheels.
Near the end of last year I decided to switch from a pure consumer of bike parts to being a retailer in the industry. In a couple of weeks, I tackled all the necessary prerequisites for a wholesale account and my dream of being a retailer was a reality.
For the first couple of months sales were going well with the majority of them being online. Unfortunately like most small business, I hit my first pain point. Instead of spending my time concentrating on building my brand and advertising, I was bogged down with the menial task of updating the stock of every item in my store and attempting to add as many of the 23,000 skus available. I knew there had to be a better way.
Unlike most of their competitors, my distributor had no API. Their site is a simple ecommerce site that requires a page load for each individual products information (ex: description, MSRP, stock…).
It was time to automate this task.
I began with a simple Ruby on Rails app which was hosted on [heroku](heroku.com) to reduce web request latency. The web scraping and site navigation was handled by the gems Mechanize and Nokogiri. This scraper required two steps to fully acquire all the data needed.
In order to get to each individual product variations page (to scrape), I first needed the Item # of each variant (as shown below) on the search results page. Through some trickery, I was able to get all product groups to list in the search results.
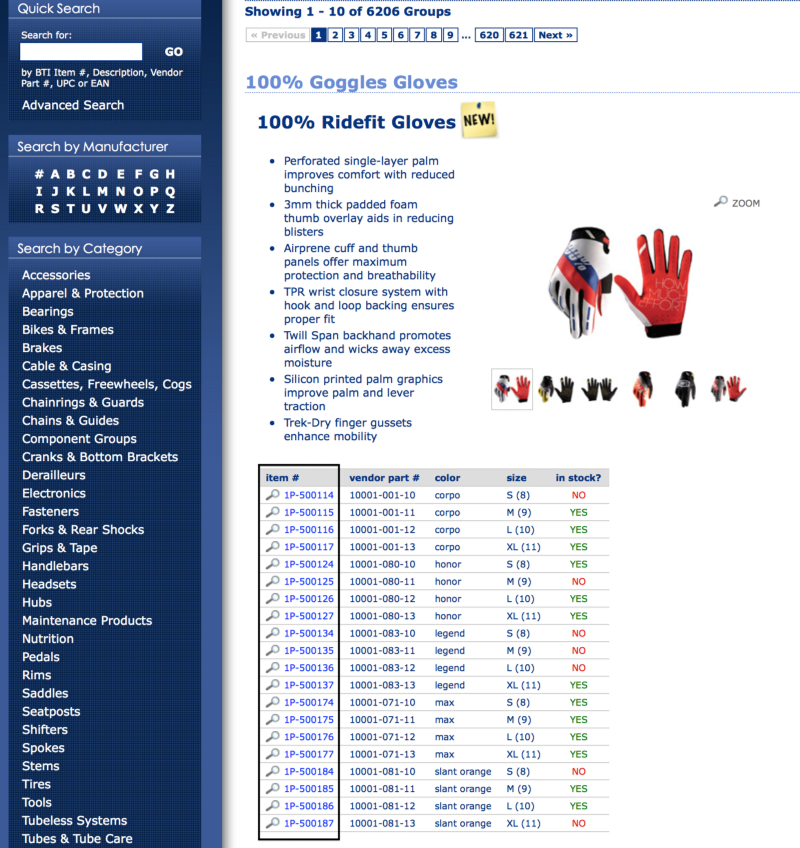
My scraper would manually enter the URL for all 621 product group pages, parse the page and insert it them into the database.
For each product group above, my script would create one product group record with an associated product for each item within it. Below is the code that tackles this task.
def self.scrape_product_groups(pages)
a = Mechanize.new
# Logs into the backend to make sure I can view all details
page = BTI.login(a)
# Pages get passed in as an array
# Allows for background jobs to process
# different pages concurrently
#
# Ex: BTI.scrape_product_groups([1,2,3])
# would scrape pages 1,2,3
pages.to_a.each do |page_num|
puts "Scraping page #{page_num}"
# Loads up product page
page = a.get("https://bti-usa.com/public/quicksearch/+/
?page=#{page_num}")
# Parses page from Mechanize to Nokogiri
raw_xml = page.parser
# Granb all product rows on the page
groupRows = raw_xml.css('.groupRow')
# Grabs product group 'bti_id' from css and parses out junk
groupRows.each do |item|
bti_id = item.attributes.first.last.value
.gsub('groupItemsDiv__num_','')
.gsub('groupItemsDiv_','')
# Creates or finds product group based on 'bti_id'
pg = ProductGroup.live.where(bti_id: bti_id).first
pg ||= ProductGroup.create(bti_id: bti_id)
# Parses product group name
pg.name = item.css('.groupTitleOpen').text
puts "Updating #{pg.name} product group"
#Build up product group description from all bullet points
pg.description = ""
item.css('.groupBullets').css('li').each do |li|
pg.description += li.text + '. '
end
# Iterates through every item number in the product group
item.css('.itemNo').each do |itemNo|
# Finds and cleans up 'bti_id'
bti_id = itemNo.css('a').text.gsub('-','')
# Creates a new product for the product group
# if none is found
product = Product.live
.where(bti_id: bti_id, product_group_id: pg.id).first
product ||= Product.create(bti_id: bti_id,
product_group_id: pg.id)
end
pg.save
end
end
end
Once all these ‘item numbers’ are collected, the second stage of the scraper kicks in.
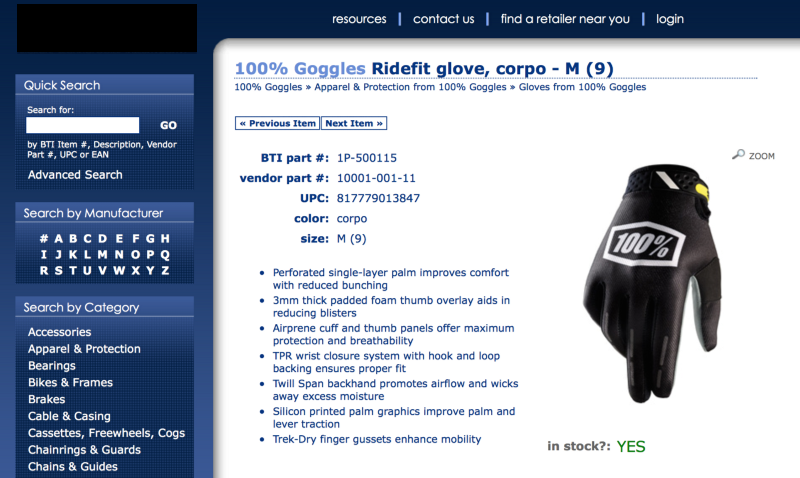
The scraper then goes to each individual page (like below) and scrapes all info on it. The different prices (cost and msrp) and stock are displayed when logged in.
The code that tackled this challenge is below:
def BTI.parse_product_info(a, product)
# Passes in 'a' = Mechanize.new and a product record
page = BTI.login(a)
# Navigates individual product page
page = a.get("https://bti-usa.com/public/item/#{product.bti_id}")
# Converts mechanize to nokogiri data
raw_xml = page.parser
# Load associated product group
pg = product.product_group
# If the product is no longer on the site,
# archive both its product group and product
# so that it will not be scraped in the future
if raw_xml.css("#errorCell").any?
pg.archive
product.archive
return
end
# Parses category from bread crumbs in header
category_parent_name = raw_xml.css('.crumbs')
.css('a').first(2).last.try(:text)
category_child_name = raw_xml.css('.crumbs')
.css('a').first(4).last.try(:text)
# Finds or create the parent and child category
category_parent = Category.where(name: category_parent_name,
parent: true).first_or_create
category_child = Category.where(name: category_child_name)
.first_or_create
# Moves the product group and/or
# product to an activated state if
# they were categorized as needed to be scraped
pg.activate if pg.scraped?
product.activate if product.scraped?
# Adds the parent and/or child category to the
# product group if not already categorized in it
pg.categories << category_parent
unless pg.categories.include?(category_parent)
pg.categories << category_child
unless pg.categories.include?(category_child)
# Parses the brand out of the page
pg.brand = raw_xml.css('.headline').css('span').text
#Updates the product group in the database
pg.save
# Grabs the image record if one exists
images = raw_xml.css(".itemTable").css("img")[1]
# If an image exists change the url to the largest
# image stored on the server
if images
image_url = images.attributes["src"].value.
gsub('thumbnails/large', 'pictures')
product.photo_url = "https://bti-usa.com" + image_url
end
# If the product requires special authorization sell, mark it
# as so
product.authorization_required =
!(!!page.form_with(:action => '/public/add_to_cart') or
!!raw_xml.search('//img/@src')
.to_s.match('/images/stockalert.gif'))
# Finds the model of the product by parsing out the brand name
product.model = pg.name.gsub(pg.brand, '')
product.save
# Parses the different product prices (Featured below)
parse_product_price(raw_xml, product)
# Parses out all product variations
raw_xml.css('.itemSpecTable').css('tr').each do |variation|
# Grabs key and value of each bullet point
key = variation.css('.specLabel').text
value = variation.css('.specData').text
# Saves mpn in product MPN field
if key == "vendor part #:"
product.mpn = value
product.save if product.changed?
end
# Parses out junk
unless key == "" or value == "" or
key == "BTI part #:" or
key == "vendor part #:" or
key == "UPC:"
variation = Variation.where(key: key.gsub(':',''),
value: value.gsub('/', ' / ')
.titleize, product_id: product.id)
.first_or_create
end
end
end
def BTI.parse_product_price(raw_xml, item)
# Grabs item name and all html containing
# price info
title_bar = raw_xml.css("h3")
name = parse_noko(title_bar).gsub("\"", "")
tds = raw_xml.css("div#bodyDiv").css("td")
# Resets product prices and stock
price = 0.0
msrp = 0.0
sale = 0.0
stock = 0
# Loops through html table and parses out
# price and stock info
# Have to loop due to BTI not believing in
# css classes
(0..100).to_a.each do |i|
unless tds[i].nil?
parsed_item = parse_noko(tds[i])
case parsed_item
when "price:"
price = parse_noko(tds[i+1], true).to_f
when "onsale!"
sale = parse_noko(tds[i+1], true).to_f
when "MSRP:"
msrp = parse_noko(tds[i+1], true).to_f
when "remaining:"
stock = parse_noko(tds[i+1], true).to_i
end
end
end
# Updates product data and
# commits it to database
item.name = name
item.msrp_price = msrp
item.sale_price = sale
item.regular_price = price
item.stock = stock
item.save
# Outputs to screen
puts " * #{name}\n"
puts " *** Price - #{price}\n"
puts " *** Stock - #{stock}\n"
puts "\n"
end
# Clean up nokogiri new line and return junk
def BTI.parse_noko(raw, with_spaces = false)
raw_text = raw.text
if with_spaces
raw_text = raw_text.gsub(" ", "")
end
raw_text.gsub("\r", "").gsub("\n","").gsub("\t","").gsub("$","").gsub(",","")
end
This second stage parsed over 23,000 items in just under two hours.
In order to get this quick time, I set up my app to process the scraping through multi-threaded background jobs using the Sidekiq. This allowed me to do 25 concurrent page requests at a time. Also if one of these request failed due to server errors on my distributor’s side, the job would be re-qued and processed a few minutes later.
By using Heroku Scheduler, this task would scale up background worker dynos when started, scrape all the data and turn them off when complete.
When it comes to lean business model, this scraper was it. The Heroku server only cost me $9 a month due to having to upgrade from the free postgres database. I didn’t have to pay for worker dynos since Heroku gives 750 free hours of server time every month.
I had all the data I needed, now it was just a matter of getting the products in front of customers!
Shopify and their API #
I began with trying to push to my existing Wordpress shop, but due to difficulties with the Woocommerce API, I knew there was a better solution.
When you need a cutting edge, simple ecommerce store with a simple API, Shopify is definitely the solution. Within 15 minutes I had the store setup with the correct sales tax amounts and merchant payment accounts (processed through Stripe) .
I went back to my app and built a rake task to manipulate my data into Shopify’s schema.
Within a day the task was done and all 23,000 sku’s were being pushed to my store.
The store was up and the products were live. For a few months I was able to concentrate on the important things and let one rake task take care of updating stock and uploading new products.
I ended up shutting down the site and shop this month (June, 2014) due to it not being worth my time. It was incredibly difficult to turn a substantial profit due to a huge amount of competition in the industry and not being able to lower my prices below MAP.
It was a fun ride but it’s time for the next venture.
Checkout the entire app: GitHub
Also I am always looking for new ideas to work on. So let me know if you are in need of a Ruby Dev to kick ass on your project.
Wanna chat? Shoot me an email
Follow me at @matteleonard to see what I’m up to next
Check out my personal site at Mattl.co